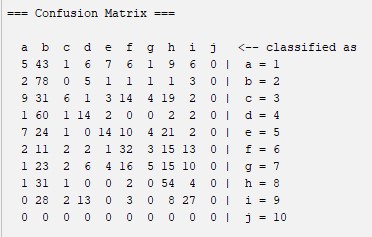
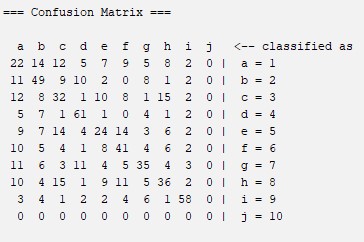
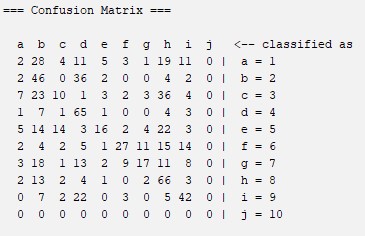
Hoeffding Tree: Is a decision tree learning method for the classification of data.It was usually used to track Web clikstreams and construct models to predict which Web hosts and Web sites a user is likely to access. For more information about this algorithm you can visit this website: What is Hoeffding Tree Algorithm?
Confussion Matrix
Percentages
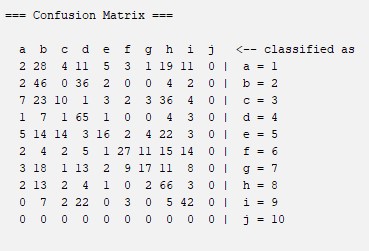
REP Tree: As in the case of the previous algorithm, is a method to generate a decision tree from a data. This method is simple but often it can be considered too agressive when it is building the knot system, as this could eliminate important data trees. This very aggressive method of possible elimination of important trees when classifying the data may be one of the reasons why the percentatge of correct classification of the images in the project is so low using said algorithm. For more information about this algorithm you can visit this website: RepTree
Confussion Matrix
Percentages
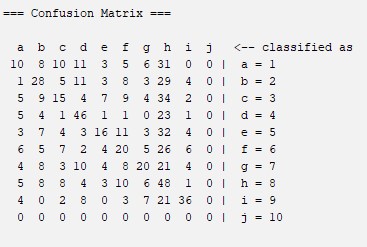
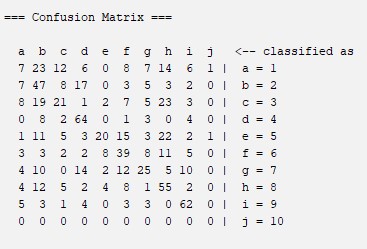
Random Tree: like the other, it is a tree-based classification and prediction method. In this method, the node starts by examining the input fields avaiable to it to find the best split. Probably, the not-high percentage of correct classification of the images is due to the fact this method is limited by the fact that it is only divided into two subgroups and so on, the fact that the combination can only be binary could be the explanation that this algorithm obtains a percentage of correct classification that is not very low but not very high either, it can be limited by this fact. For more information about this algorithm you can visit this website: Random Tree
Confussion Matrix
Percentages
Random Forest: is an ensemble learning method for classification, regression... (other functions) of data. This method construct a multitude of decisions trees. The fact that the percentages of correct classification of the images is higher in Random Forest is because this method has a generalization capacity for many problems. Also, this percentage is due to the fact that by combining the different result trees, their errors are compensated with others and we thus obtain a prediction that generalizes more correctly. For more information about this algorithm you can visit this website: Random Forest
Confussion Matrix
Percentages
J48: is a machine learning decision tree classification algorithm that classify and examine the data categorically and continuously. This method generate a decision tree that is generated by C4.5 (an extendion of ID3). It is also known as a statical classifier. For a decision tree classification, we need a database. The fact that we have obtained a fairly higj percentage compared to others may be due to the fact that the J48 algorithm allows us to make, in many cases, quite accurate predictions since it deals with the problems that arise from missing data values, from pruning, from the estimation of error rates and also, for example, from the induction complexity of decision trees. For more information about this algorithm you can visit this website: J48
Confussion Matrix
Percentages
Navie Bayes Updateable: is a class for a Naive Bayes classifier using estimator classes. This is the updateable version of NaiveBayes. This classifier will use a default precision of 0.1 for numeric attributes when buildClassifier is called with zero training instances. For more information about this algorithm you can visit this website: Naive Bayes Updateable
Confussion Matrix
Percentages
Naive Bayes Multinominal Text: is a type of classifier that is suitable for the classification with discrete features. This type of distribution, the multinominal, normally requires integer feature counts. Multinominal Naive Bayes is a probabilistic learning method and it's based on the Bayes Theorem. This method calculates the probability of each tag for a given sample and after that it gives the tag with the highest probability as output. Probably, the reason the percentage is so low is because the prediction accuracy of this algorithm is lower than that of other probability algorithms. For more information about this algorithm you can visit this website: Naive Bayes Multinominal
Confussion Matrix
Percentages
Bayes Net: is a type of probabilistic graphical model of data that uses Bayesian inference for probability computations. This type of algorithm, the Bayesian networks, aim to model conditional dependance, and therefore causation, by representingconditional dependece by edges in a directed graph. As a result of the little information that we find about this algorithm on the internet, the explanation of the resulting percentage cannot be attempted correctly. For more information about this algorithm you can visit this website: Bayes Net
Confussion Matrix
Percentages
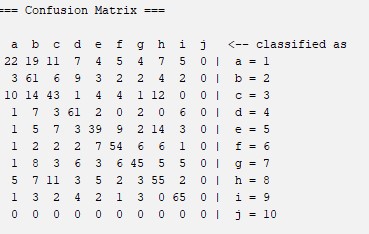
Naive Bayes: in probability theory and data mining, a Naive Bays classifier is a probabilistic classifier based on Bayes theorem and some additional simplifications, which are usually summarizedin the hypothesis of independence between the predictor varaibles, that it is called naive, that is ingenious. The percentage of correct classification of the images is neither very high nor very low, compared to other previously appeared percentages, but it must be said that the Naive Bayes estimates can be erroneous in some cases, so we should not take it very seriously their probability outputs. For more information about this algorithm you can visit this website: Naive Bayes
Confussion Matrix
Percentages
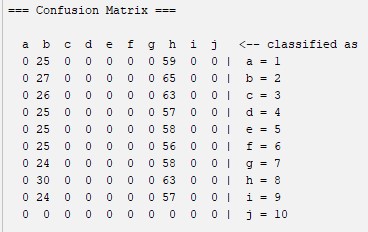
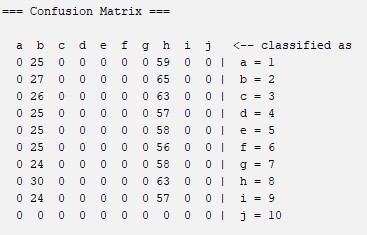
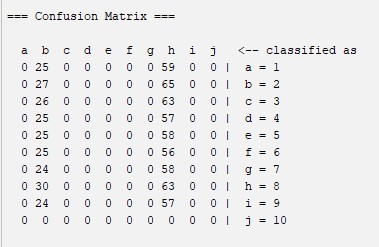
Zero R: is the simplest classification method odf data which relies on the target and ignores all predictors. ZeroR classifier simply predicts the majority category. Although there is no predictability power in ZeroR, it is useful for determining a baseline performance as a benchmark for other classification methods. Construct a frequency table and select its most frequent value. The fact that it is one of the simplest classification methods may be the reason why the percentage of correct classification is so low. A simplification of the knot method can lead to these results. For more information about this algorithm you can visit this website: ZeroR
Confussion Matrix
Percentages
Results
The best results of percentages of correct classification of the images are those provided by the Random Forest algorithm, J48, Bayes Net, Naive Bayes and Naive Bayes Updateable. Most of them algorithms that work through a system of decision trees and the Bayesian method.